SciMLBenchmarks.jl
SciMLBenchmarks.jl: Benchmarks for Scientific Machine Learning (SciML) and Equation Solvers

![]()
![]()

SciMLBenchmarks.jl holds webpages, pdfs, and notebooks showing the benchmarks for the SciML Scientific Machine Learning Software ecosystem, including:
- Benchmarks of equation solver implementations
- Speed and robustness comparisons of methods for parameter estimation / inverse problems
- Training universal differential equations (and subsets like neural ODEs)
- Training of physics-informed neural networks (PINNs)
- Surrogate comparisons, including radial basis functions, neural operators (DeepONets, Fourier Neural Operators), and more
The SciML Bench suite is made to be a comprehensive open source benchmark from the ground up, covering the methods of computational science and scientific computing all the way to AI for science.
Rules: Optimal, Fair, and Reproducible
These benchmarks are meant to represent good optimized coding style. Benchmarks are preferred to be run on the provided open benchmarking hardware for full reproducibility (though in some cases, such as with language barriers, this can be difficult). Each benchmark is documented with the compute devices used along with package versions for necessary reproduction. These benchmarks attempt to measure in terms of work-precision efficiency, either timing with an approximately matching the error or building work-precision diagrams for direct comparison of speed at given error tolerances.
If any of the code from any of the languages can be improved, please open a pull request.
Results
To view the results of the SciML Benchmarks, go to benchmarks.sciml.ai. By default, this will lead to the latest tagged version of the benchmarks. To see the in-development version of the benchmarks, go to https://benchmarks.sciml.ai/dev/.
Static outputs in pdf, markdown, and html reside in SciMLBenchmarksOutput.
Citing
To cite the SciML Benchmarks, please cite the following:
@article{rackauckas2019confederated,
title={Confederated modular differential equation APIs for accelerated algorithm development and benchmarking},
author={Rackauckas, Christopher and Nie, Qing},
journal={Advances in Engineering Software},
volume={132},
pages={1--6},
year={2019},
publisher={Elsevier}
}
@article{DifferentialEquations.jl-2017,
author = {Rackauckas, Christopher and Nie, Qing},
doi = {10.5334/jors.151},
journal = {The Journal of Open Research Software},
keywords = {Applied Mathematics},
note = {Exported from https://app.dimensions.ai on 2019/05/05},
number = {1},
pages = {},
title = {DifferentialEquations.jl – A Performant and Feature-Rich Ecosystem for Solving Differential Equations in Julia},
url = {https://app.dimensions.ai/details/publication/pub.1085583166 and http://openresearchsoftware.metajnl.com/articles/10.5334/jors.151/galley/245/download/},
volume = {5},
year = {2017}
}
Current Summary
The following is a quick summary of the benchmarks. These paint broad strokes over the set of tested equations and some specific examples may differ.
Non-Stiff ODEs
- OrdinaryDiffEq.jl’s methods are the most efficient by a good amount
- The
Vernmethods tend to do the best in every benchmark of this category - At lower tolerances,
Tsit5does well consistently. - ARKODE and Hairer’s
dopri5/dop853perform very similarly, but are both far less efficient than theVernmethods. - The multistep methods,
CVODE_Adamsandlsoda, tend to not do very well. - The ODEInterface multistep method
ddeabmdoes not do as well as the other multistep methods. - ODE.jl’s methods are not able to consistently solve the problems.
- Fixed time step methods are less efficient than the adaptive methods.
Stiff ODEs
- In this category, the best methods are much more problem dependent.
- For smaller problems:
Rosenbrock23,lsoda, andTRBDF2tend to be the most efficient at high tolerances.Rodas4PandRodas5Ptend to be the most efficient at low tolerances.
- For larger problems (Filament PDE):
FBDFandQNDFdo the best at all normal tolerances.- The ESDIRK methods like
TRBDF2andKenCarp4can come close.
radauis always the most efficient when tolerances go to the low extreme (1e-13)- Fixed time step methods tend to diverge on every tested problem because the high stiffness results in divergence of the Newton solvers.
- ARKODE is very inconsistent and requires a lot of tweaking in order to not
diverge on many of the tested problems. When it doesn’t diverge, the similar
algorithms in OrdinaryDiffEq.jl (
KenCarp4) are much more efficient in most cases. - GeometricIntegrators.jl fails to converge on any of the tested problems.
Dynamical ODEs
- Higher order (generally order >=6) symplectic integrators are much more efficient than the lower order counterparts.
- For high accuracy, using a symplectic integrator is not preferred. Their extra cost is not necessary since the other integrators are able to not drift simply due to having low enough error.
- In this class, the
DPRKNmethods are by far the most efficient. TheVernmethods do well for not being specific to the domain.
Non-Stiff SDEs
- For simple 1-dimensional SDEs at low accuracy, the
EMandRKMilmethods can do well. Beyond that, they are simply outclassed. - The
SRAandSRImethods both are very similar within-class on the simple SDEs. SRA3is the most efficient when applicable and the tolerances are low.- Generally, only low accuracy is necessary to get to sampling error of the mean.
- The adaptive method is very conservative with error estimates.
Stiff SDEs
- The high order adaptive methods (
SRIW1) generally do well on stiff problems. - The “standard” low-order implicit methods,
ImplicitEMandImplicitRK, do not do well on all stiff problems. Some exceptions apply to well-behaved problems like the Stochastic Heat Equation.
Non-Stiff DDEs
- The efficiency ranking tends to match the ODE Tests, but the cutoff from low to high tolerance is lower.
Tsit5does well in a large class of problems here.- The
Vernmethods do well in low tolerance cases.
Stiff DDEs
- The Rosenbrock methods, specifically
Rodas5P, perform well.
Parameter Estimation
- Broadly two different approaches have been used, Bayesian Inference and Optimisation algorithms.
- In general it seems that the optimisation algorithms perform more accurately but that can be attributed to the larger number of data points being used in the optimisation cases, Bayesian approach tends to be slower of the two and hence lesser data points are used, accuracy can increase if proper data is used.
- Within the different available optimisation algorithms, BBO from the BlackBoxOptim package and GN_CRS2_LM for the global case while LD_SLSQP,LN_BOBYQA and LN_NELDERMEAD for the local case from the NLopt package perform the best.
- Another algorithm being used is the QuadDIRECT algorithm, it gives very good results in the shorter problem case but doesn’t do very well in the case of the longer problems.
- The choice of global versus local optimization make a huge difference in the timings. BBO tends to find the correct solution for a global optimization setup. For local optimization, most methods in NLopt, like :LN_BOBYQA, solve the problem very fast but require a good initial condition.
- The different backends options available for Bayesian method offer some tradeoffs between time, accuracy and control. It is observed that sufficiently high accuracy can be observed with any of the backends with the fine tuning of stepsize, constraints on the parameters, tightness of the priors and number of iterations being passed.
Interactive Notebooks
To generate the interactive notebooks, first install the SciMLBenchmarks, instantiate the
environment, and then run SciMLBenchmarks.open_notebooks(). This looks as follows:
]add SciMLBenchmarks#master
]activate SciMLBenchmarks
]instantiate
using SciMLBenchmarks
SciMLBenchmarks.open_notebooks()
The benchmarks will be generated at your pwd() in a folder called generated_notebooks.
Note that when running the benchmarks, the packages are not automatically added. Thus you will need to add the packages manually or use the internal Project/Manifest tomls to instantiate the correct packages. This can be done by activating the folder of the benchmarks. For example,
using Pkg
Pkg.activate(joinpath(pkgdir(SciMLBenchmarks),"benchmarks","NonStiffODE"))
Pkg.instantiate()
will add all of the packages required to run any benchmark in the NonStiffODE folder.
Contributing
All of the files are generated from the Weave.jl files in the benchmarks folder of the SciMLBenchmarks.jl repository. The generation process runs automatically,
and thus one does not necessarily need to test the Weave process locally. Instead, simply open a PR that adds/updates a
file in the benchmarks folder and the PR will generate the benchmark on demand. Its artifacts can then be inspected in the
Buildkite as described below before merging. Note that it will use the Project.toml and Manifest.toml of the subfolder, so
any changes to dependencies requires that those are updated.
Reporting Bugs and Issues
Report any bugs or issues at the SciMLBenchmarks repository.
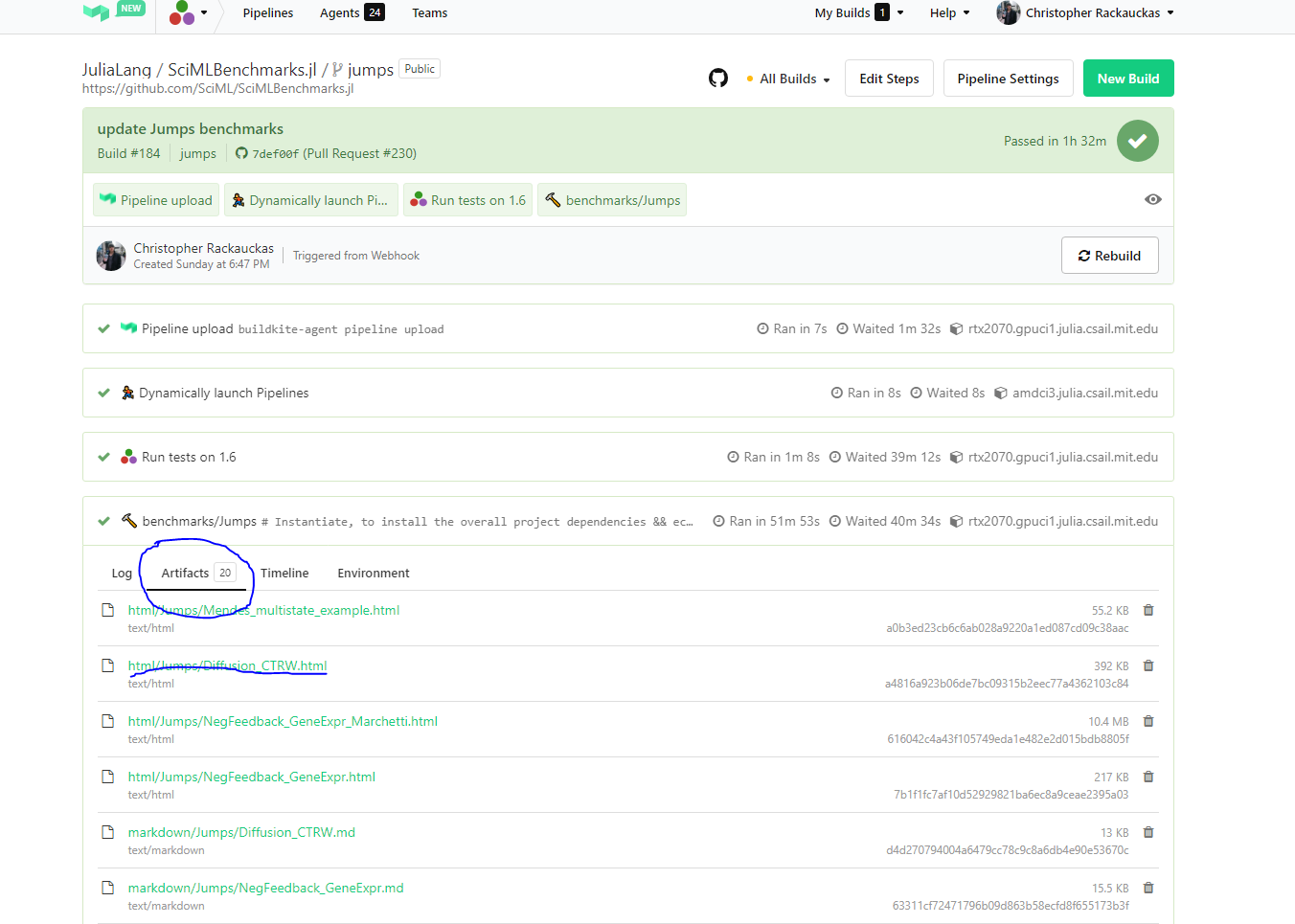
Inspecting Benchmark Results
To see benchmark results before merging, click into the BuildKite, click onto Artifacts, and then investigate the trained results.
Manually Generating Files
All of the files are generated from the Weave.jl files in the benchmarks folder. To run the generation process, do for example:
]activate SciMLBenchmarks # Get all of the packages
using SciMLBenchmarks
SciMLBenchmarks.weave_file(joinpath(pkgdir(SciMLBenchmarks),"benchmarks","NonStiffODE"),"linear_wpd.jmd")
To generate all of the files in a folder, for example, run:
SciMLBenchmarks.weave_folder(joinpath(pkgdir(SciMLBenchmarks),"benchmarks","NonStiffODE"))
To generate all of the notebooks, do:
SciMLBenchmarks.weave_all()
Each of the benchmarks displays the computer characteristics at the bottom of the benchmark. Since performance-necessary computations are normally performed on compute clusters, the official benchmarks use a workstation with an AMD EPYC 7502 32-Core Processor @ 2.50GHz to match the performance characteristics of a standard node in a high performance computing (HPC) cluster or cloud computing setup.
Choosing a Reference Solution
For almost all equations, there is no analytical solution. A low tolerance reference solution is required in order to compute the error. However, there are many questions as to the potential of biasing the results via a reference computed from a given program. If we use a reference solution from Julia, does that make our errors lower?
The answer is no because all of the equation solvers should be convergent to the same solution. Because of this, it does not matter which solver is used to generate the reference solution. However, caution is required to ensure that the reference solution is sufficiently accurate.
Thankfully, there’s a very clear indicator of when a reference solution is not sufficiently correct. Because all other methods will be converging to a different solution, there will be a digit of accuracy at which all other solutions stop converging to the reference. If this occurs, all solutions will give a straight line, you can see there here:

In this image (taken from the TransistorAmplifierDAE benchmark), the second Rodas5P and Rodas4 are from a different problem implementation, and you can see they hit lower errors. But all of the others use the same reference solution and seem to “hit a wall” at around 1e-5. This is because the chosen reference solution was only 1e-5 accurate. Changing to a different reference solution makes them all converge:

This shows that all that truly matters is that the chosen reference is sufficiently accurate, and any walling behavior is an indicator that some method in the benchmark set is more accurate than the reference (in which case the benchmark should be updated to use the more accurate reference).